NVIDIA Unveils KVzap: A Revolutionary Method for Efficient Key-Value Cache Pruning

Understanding KVzap: A New Approach to Key-Value Cache Pruning
In the fast-evolving world of artificial intelligence, the efficiency of transformer models is paramount. NVIDIA’s recently open-sourced KVzap brings a groundbreaking solution to the problem of optimizing key-value cache pruning. By tapping into advanced techniques, KVzap can achieve a remarkable compression rate of 2x to 4x while maintaining accuracy, making it a breakthrough for large-scale models. This innovation not only enhances performance but also opens up new possibilities for the deployment of AI in resource-constrained environments.
The Challenge of Key-Value Cache in Transformers

As the length of context in transformer models stretches into the tens and hundreds of thousands of tokens, the key-value (KV) cache in decoder layers becomes increasingly cumbersome. This cache, which holds keys and values for each layer and head, can balloon up to 335 GB in size for models like Llama1-65B at 128k tokens, directly impacting batch sizes and the time taken to generate the first token. Such large cache sizes pose challenges in memory management and computational overhead, necessitating innovative solutions to speed up the process.
Current Solutions and Limitations
While existing transformer models employ various methods to compress cache size along different axes, none fully tackle the challenge posed by the sequence axis. Techniques such as Grouped Query Attention, which shares keys and values across multiple queries, have shown promise, achieving impressive compression ratios in models like Llama3 and Qwen3. However, they still fail to address the key need for effective cache pruning, where unnecessary entries are removed without affecting future token generation. On top of that, many of these methods require significant computational resources, which can be a limiting factor in practical applications.
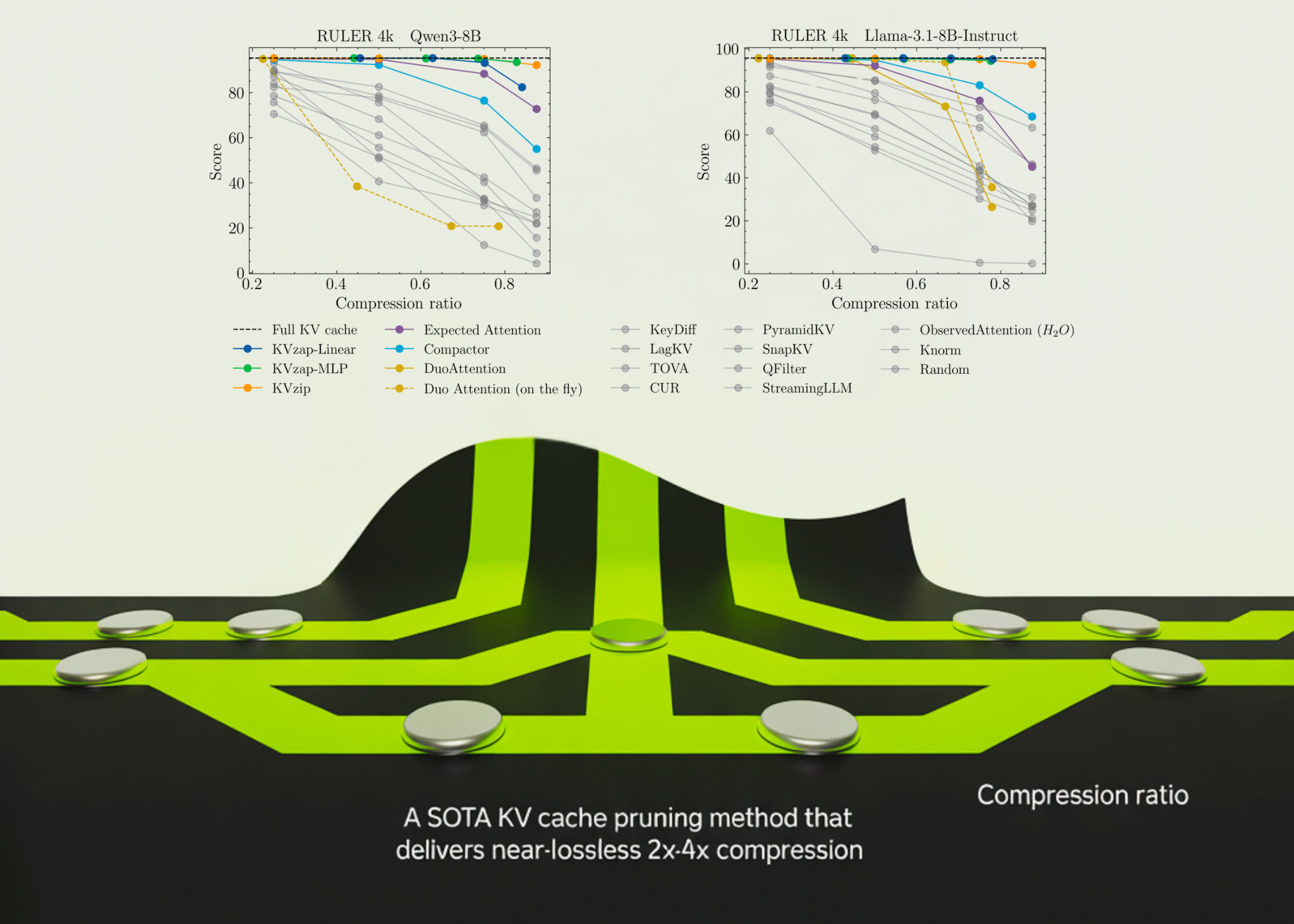
NVIDIA’s KVpress project has aggregated over twenty pruning methods, providing a public leaderboard on Hugging Face to evaluate their effectiveness. Among these, KVzip stands out as a solid baseline, working with a full scoring system to assess cache entry importance. However, its reliance on extended prompts for scoring makes it too slow for real-time applications. This highlights the need for a more efficient approach that balances performance with practicality, particularly in scenarios where speed is important.
Introducing KVzap: A Surrogate Model for Improved Performance
KVzap reimagines cache pruning by introducing a surrogate model that directly evaluates hidden states. Instead of relying on the computationally intensive KVzip, this innovative method uses a simpler approach to predict importance scores for each KV head. Two architectures are considered for implementation: a basic linear layer and a more sophisticated two-layer MLP that incorporates GELU activation. This flexibility allows researchers to choose the model that best fits their requirements while ensuring high performance and adaptability.
Training Methodology
The research team trained KVzap using a diverse dataset of prompts sourced from the Nemotron Pretraining Dataset. By filtering and carefully selecting prompts, they generated approximately 1.2 million training pairs to enable the surrogate model to learn effectively. The result was a significant correlation between the predicted scores and those from the previous oracle-based methods, reaching between 0.63 and 0.77. This strong correlation demonstrates the model’s ability to learn and generalize from the training data, further solidifying its potential for real-world applications.
Inference Efficiency and Adaptability
During inference, KVzap processes hidden states, producing scores for each cache entry. Entries with scores below a certain threshold are pruned, while a sliding window of the most recent tokens is preserved. This adaptive mechanism allows for varying compression ratios based on the specific prompt, exhibiting a remarkable up to 20 percent variation across different prompts at the same threshold. This feature is particularly valuable in dynamic environments where the nature of input data can change rapidly, enabling the model to maintain optimal performance regardless of the context.
Experimental Results: Performance Evaluation
KVzap’s real-world performance has been assessed across several benchmarks, including RULER, LongBench, and AIME25. These tests revealed that KVzap can effectively balance cache compression while maintaining accuracy, showing minimal deviation from the full cache baselines. For instance, on RULER, KVzap was able to efficiently reduce cache size while keeping accuracy within a narrow margin of the full cache. This balance is major, as it ensures that performance doesn’t suffer as cache sizes are minimized.

Specifically, models such as Qwen3-8B exhibited impressive results, achieving over 70% cache removal on multiple tasks without sacrificing overall performance. This level of efficiency is particularly important for applications requiring real-time processing and decision-making. What’s more, the ability to remove such a substantial portion of the cache without compromising on accuracy signifies a major step forward in optimizing transformer architectures.
Key Takeaways and Future Implications
- KVzap presents a novel input-adaptive method for approximating KVzip+, effectively predicting the importance of cache entries from hidden states.
- It utilizes a global score threshold and a sliding window mechanism, allowing for dynamic adaptation to varying information densities in prompts.
- With significant compression rates of 2x to 4x demonstrated across various models and benchmarks, KVzap sets a new standard in the realm of transformer efficiency.
- The adoption of KVzap could pave the way for more advanced AI applications, particularly in settings where computational resources are limited.
- As AI continues to integrate into more sectors, tools like KVzap will play a key role in enhancing model performance while reducing infrastructure costs.
Frequently Asked Questions
1. what’s KVzap?
KVzap is an innovative key-value cache pruning method developed by NVIDIA that optimizes the efficiency of transformer models by compressing cache size while maintaining accuracy.
2. How does KVzap work?
KVzap uses a surrogate model to predict the importance of cache entries based on hidden states, allowing for effective pruning of low-importance entries during inference.
3. What are the training datasets used for KVzap?
The model was trained using the Nemotron Pretraining Dataset, which comprises diverse prompts filtered to enhance learning effectiveness.
4. How does KVzap perform compared to previous models?
KVzap has demonstrated significant improvements, achieving up to 4x compression rates while keeping task accuracy close to the full cache baseline.
5. Can KVzap be implemented in real-time applications?
Yes, KVzap’s efficiency makes it suitable for real-time applications, enabling faster response times without compromising performance.
Worth Checking Out: This “quantum-safe” Bitcoin idea removes Taproot’s key-path — and raises fees on purpose
You Might Also Like
