Introducing LLMRouter: A Smart Routing System for Optimizing LLM Model Selection
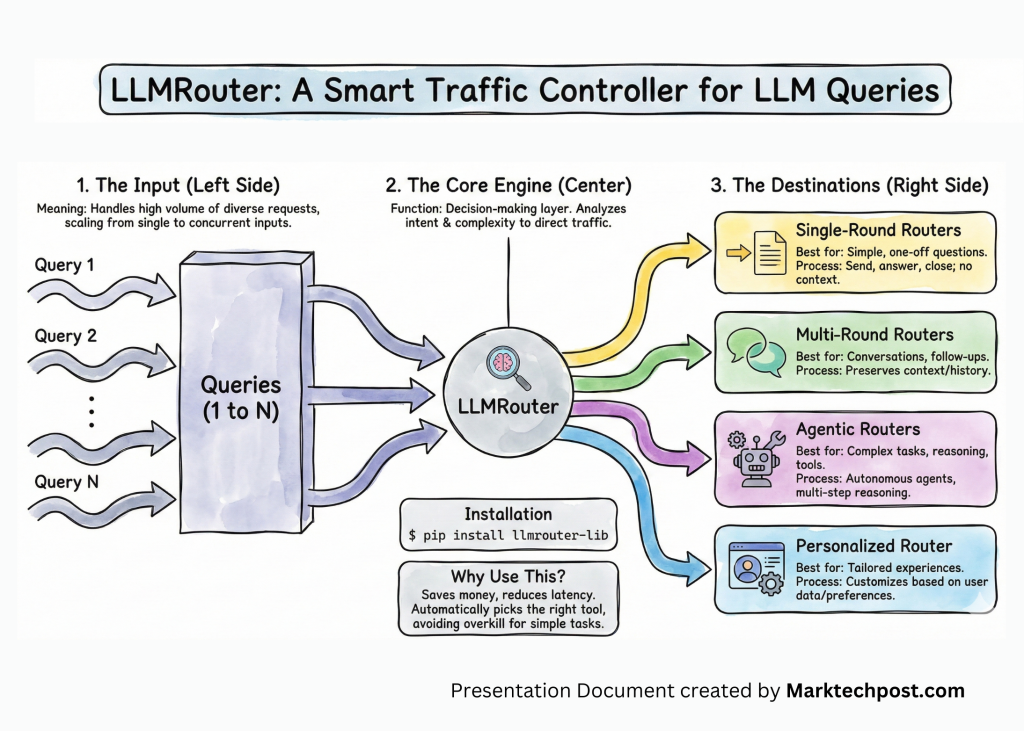

what’s LLMRouter?
LLMRouter is an innovative open-source routing library developed by the U Lab at the University of Illinois at Urbana-Champaign. It addresses the challenges of model selection for Large Language Models (LLMs) by acting as an intermediary between applications and a diverse range of LLMs. The beauty of LLMRouter lies in its ability to dynamically select the most appropriate model for each query based on various factors like task complexity, quality requirements, and cost-effectiveness. This functionality is neatly wrapped in a unified Python API and command-line interface (CLI). The design philosophy behind LLMRouter emphasizes efficiency and adaptability, enabling smooth integration into existing systems and workflows.
Key Features

- Supports over 16 routing models
- Includes a full data generation pipeline across 11 benchmarks
- Features a flexible plugin system for custom routers
Organizing Routing Models
LLMRouter categorizes its routing algorithms into four distinct families, maximizing efficiency and usability:
1. Single-Round Routers
This family spans models like knnrouter, svmrouter, mlprouter, and more. These routers employ various strategies, including:
- K-Nearest Neighbors
- Support Vector Machines
- Multilayer Perceptrons
- Matrix Factorization
- Elo Rating
- Automatic Model Mixing
- Graph-Based Routing
By working with these diverse strategies, Single-Round Routers can quickly analyze and respond to queries, making them ideal for applications where rapid responses are required. Their adaptability allows developers to choose the most suitable router based on specific use cases, whether that be for general inquiries or complex problem-solving scenarios.
2. Multi-Round Routers
The router_r1 model is a pre-trained instance of Router R1, which handles multi-LLM routing and aggregation as a sequential decision-making process. Here, the router itself acts as an LLM, alternating between internal reasoning and external model calls. It’s trained using reinforcement learning, balancing format, results, and costs. This multi-round approach allows for a more nuanced understanding of user queries, as it can process follow-up questions and refine responses based on previous interactions, resulting in a more coherent dialogue.
3. Personalized Routers
The gmtrouter is notable for its graph-based approach to understanding user preferences. It models interactions as a heterogeneous graph involving users, queries, responses, and models, employing a message-passing architecture to derive specific routing preferences from minimal interaction data. This method demonstrates significant improvements in accuracy and area under the curve (AUC) compared to non-personalized routers. Beyond that, the personalized routing capabilities ensure that users receive tailored responses that align closely with their individual needs and contexts, ultimately enhancing user satisfaction and engagement.
4. Agentic Routers
These routers extend the concept to multi-step reasoning workflows. For instance, knnmultiroundrouter utilizes K-Nearest Neighbor reasoning over multi-turn interactions, catering to detailed tasks. Meanwhile, llmmultiroundrouter provides an agentic LLM router capable of multi-step routing without requiring its own training loop. This allows for greater flexibility in handling complex queries that may require multiple layers of reasoning and interaction, making it particularly useful in applications such as customer support or advanced data analysis.
Data Generation Pipeline
LLMRouter comes equipped with a in-depth data generation pipeline that transforms standard benchmarks and LLM outputs into organized routing datasets. It supports eleven popular benchmarks, including Natural QA, Trivia QA, MMLU, and more. The data generation process consists of three key stages:
- Extracting queries and truth labels, creating training and testing JSONL splits.
- Building embeddings for candidate LLMs.
- Evaluating LLM responses and integrating scores with embeddings into routing records.

This pipeline produces various output formats, including query files and routing data JSONL files, allowing for easy integration and configuration through YAML files. Thus, engineers can effortlessly direct the scripts to new datasets without needing to alter any core code. This modularity not only speeds up the development process but also empowers teams to focus on improving model performance and user experience, rather than on the intricacies of data handling.
Chat Interface and Plugin Capabilities
For those who prefer an interactive environment, LLMRouter offers an easy-to-use chat interface built with Gradio. This enables users to initiate chat sessions over any configured router, with options to customize the host and port. The interface is designed to visualize model selections in real-time, driven by the same configurations used for batch processing. This real-time feedback mechanism helps users understand the routing decisions made by the system, fostering a more intuitive interaction.
On top of that, LLMRouter includes a versatile plugin system for adding custom routers. Developers can create new routers under the custom_routers directory, subclassing the MetaRouter and implementing the required methods. The plugin discovery feature automatically scans designated directories, making it simple to find and work with custom routers. This extensibility is vital for organizations aiming to tailor the routing capabilities to their unique requirements, allowing for continuous improvement and adaptation as new models and techniques emerge.
Key Takeaways
- Routing as a Core Abstraction: LLMRouter centralizes model selection as a key system task, enhancing the efficiency of applications making use of multiple LLMs.
- In-depth Router Families: The library standardizes over 16 models across four routing families, offering flexibility and ease of use.
- Multi-Round Reinforcement Learning: The integration of Router R1 utilizes a reinforcement learning framework that efficiently balances performance and costs.
- Graph-Based Personalization: GMTRouter’s innovative graph-based approach dramatically improves user-specific routing preferences.
- Expandable Infrastructure: With a strong data pipeline and the ability to introduce custom routers, LLMRouter provides a scalable solution for various use cases.
Conclusion
LLMRouter represents a significant advancement in the field of LLM model selection. By offering a unified and flexible routing solution, it empowers developers and researchers to optimize their applications more effectively. The emphasis on personalization, efficiency, and extensibility makes LLMRouter a valuable tool in the evolving scene of AI-driven applications, ensuring that users can achieve superior performance regardless of their specific requirements.
FAQs
what’s LLMRouter?
LLMRouter is an open-source routing library designed to smooth out model selection for large language models, optimizing performance based on various criteria.
How many routing models does LLMRouter support?
LLMRouter supports over 16 different routing models organized into four main families.
Can I create custom routers with LLMRouter?
Yes, LLMRouter provides a plugin system that allows developers to create and integrate custom routers easily.
What benchmarks does LLMRouter’s data generation pipeline support?
The pipeline supports 11 benchmarks, including Natural QA, Trivia QA, and MMLU, among others.
How does LLMRouter personalize model selection?
Through its GMTRouter, LLMRouter uses a graph-based approach to learn user preferences from few-shot interaction data, improving routing accuracy.
You Might Also Like
