NVIDIA and Mistral AI Revolutionize AI Performance with Enhanced Inference Speed

Introduction
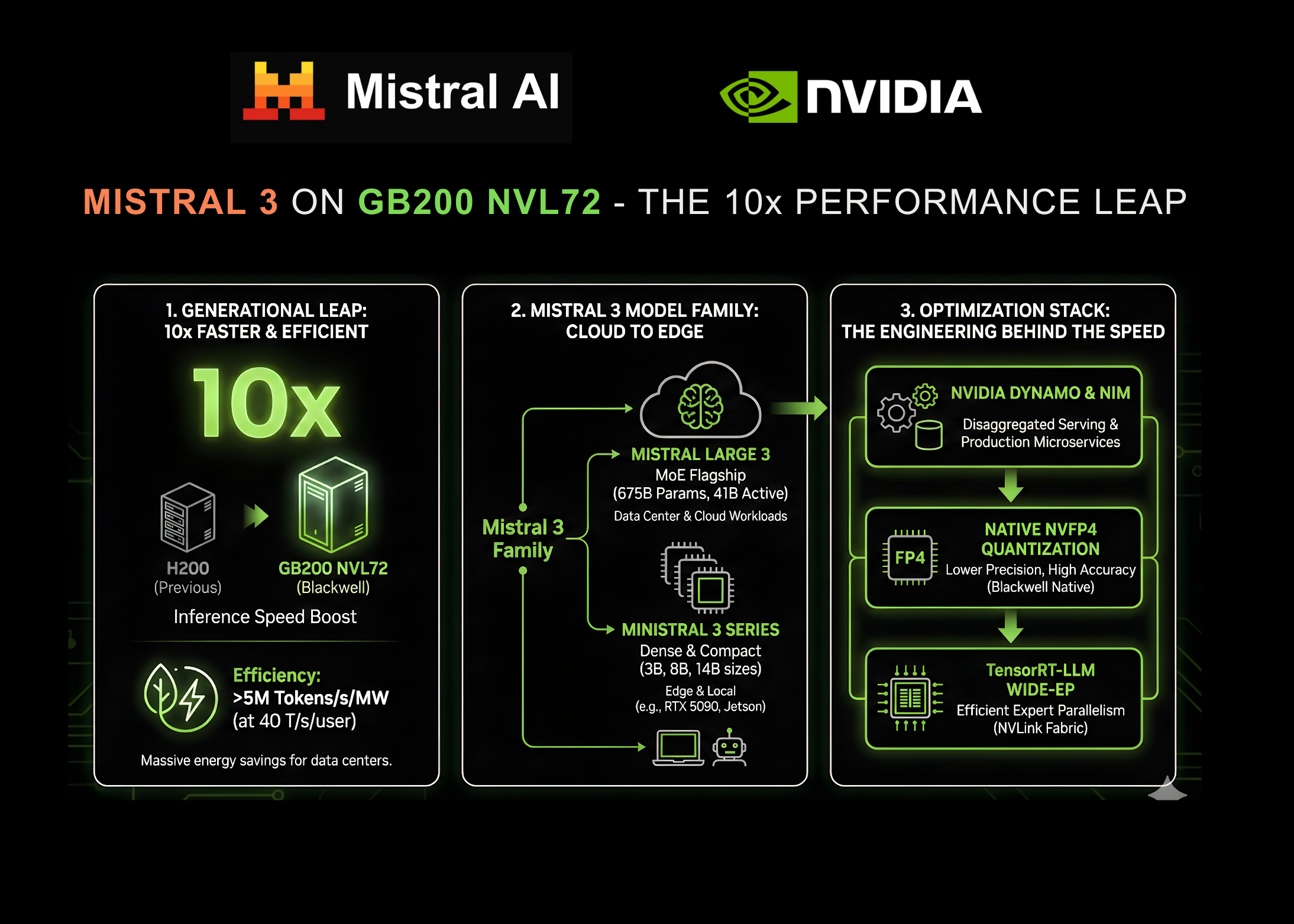
NVIDIA and Mistral AI have joined forces to make a significant breakthrough in AI performance. Their collaboration has led to the introduction of the Mistral 3 family of models, which now delivers inference speeds that are up to ten times faster than the previous generation. This enhancement aims to address longstanding challenges in latency and cost, making it easier for enterprises to deploy powerful AI systems.
Why This Matters

With the increasing demand for advanced AI applications, businesses need efficiency and speed that traditional systems struggle to provide. The Mistral 3 models are specifically designed for NVIDIA’s GB200 NVL72 systems, allowing for faster processing of complex reasoning tasks. This means businesses can now implement real-time applications without facing the usual delays.
The Leap in Inference Speed
The enhanced performance is particularly notable when comparing the new models to NVIDIA’s previous H200 systems. The transition to the GB200 NVL72 represents a generational leap, with the potential to process over 5 million tokens per second per megawatt, all while maintaining user interactivity. This kind of efficiency is game-changing, especially for data centers facing power restrictions.
The Mistral 3 Family: A Closer Look
The Mistral 3 family includes a variety of models, each optimized for different needs, from extensive data center workloads to edge devices. At the forefront is the Mistral Large 3 model, boasting an impressive 675 billion parameters and designed for high-level reasoning tasks.
Mistral Large 3: Features and Specifications
- Total Parameters: 675 Billion
- Active Parameters: 41 Billion
- Context Window: 256K tokens
This flagship model offers capabilities that rival some of the top closed models, all while maintaining open weights for flexibility in deployment. (CoinDesk)
Ministral 3: Versatile and Efficient
Complementing the Mistral Large 3 are the Ministral 3 models, designed for speed and versatility. They come in various sizes, including 3B, 8B, and 14B parameters, and are built to excel in accuracy benchmarks while managing resource use effectively. You might also enjoy our guide on Aave’s Dominance in DeFi Lending: Risks and Implications.
Behind the Performance Improvements
The tenfold increase in performance isn’t just about faster hardware; it’s also about smart engineering. NVIDIA and Mistral engineers have worked together using an ‘extreme co-design’ approach, merging software and hardware optimally.
Innovative Technologies Driving Speed
One of the standout technologies is Wide Expert Parallelism (Wide-EP), which significantly optimizes the performance of Mistral models on the GB200 NVL72. This method ensures that the model’s size doesn’t create bottlenecks in communication, allowing for high bandwidth and low latency.
Quantization Innovations
Another breakthrough is the introduction of NVFP4 quantization, a format tailored for the Blackwell architecture. This ensures that despite using lower precision in some areas, the overall accuracy of the model remains intact. The result is a model that can be deployed without compromising performance.
Scalable Solutions for All
Whether it’s for expansive cloud data centers or edge devices, the Mistral 3 series caters to a wide range of applications. For instance, the models are optimized for NVIDIA’s RTX graphics cards and Jetson modules, making them versatile enough for various real-world uses.

Performance on Different Hardware
- RTX 5090: The Ministral-3B variant can achieve speeds of 385 tokens per second.
- Jetson Thor: The Ministral-3-3B-Instruct model reaches 52 tokens per second, scaling up to 273 tokens per second with multiple concurrent requests.
This flexibility makes it easier for developers to integrate these models into existing systems without extensive modifications. For more tips, check out Why Bitcoin Is Struggling While BNB Thrives.
Future-Proofing AI Development
NVIDIA is also working with a variety of open-source projects to ensure that these models can be utilized broadly. This includes partnerships with frameworks like Llama.cpp and vLLM, which enhances local development capabilities. (Bitcoin.org)
Enterprise Integration with NVIDIA NIM
To make adoption smoother for businesses, NVIDIA is offering the Mistral models through its NIM microservices. This means companies can deploy state-of-the-art AI with minimal setup, gaining access to the substantial performance enhancements without needing deep technical expertise.
Conclusion: Setting New Standards in Open AI
The collaboration between NVIDIA and Mistral AI is reshaping the market of AI performance. By providing open-source models with impressive speed and efficiency, the two companies aren’t only catering to the demands of enterprises but also fostering innovation in the AI community.
FAQs
what’s the Mistral 3 family of models?
The Mistral 3 family consists of advanced AI models designed for high-speed inference and optimized for NVIDIA hardware, delivering exceptional performance for various applications.
How much faster are the new models compared to previous generations?
The new Mistral 3 models can run inference tasks up to ten times faster than the prior H200 generation, making them suitable for real-time applications.
What makes the Mistral Large 3 model unique?
Mistral Large 3 is notable for its vast number of parameters (675 billion) and its ability to perform complex reasoning tasks while maintaining open weights for flexibility.
How does the NVFP4 quantization work?
NVFP4 quantization allows for reduced compute and memory costs while preserving accuracy, making it efficient for deploying large models.
Where can I find more information about these models?
You can learn more about NVIDIA’s AI technologies on their official website: NVIDIA AI and Mistral AI’s offerings at Mistral AI.
You Might Also Like
